Hashowanie generuje stałej długości ciąg znaków (tzw. hash) na podstawie dowolnych długich danych wejściowych. Wynikowy hash wygląda na losowy ciąg znaków, jednak podając niezmienione dane wejściowe, otrzymamy zawsze taki sam wynik. Nawet najmniejsza zmiana w danych wejściowych, wygeneruje kompletnie inny hash.
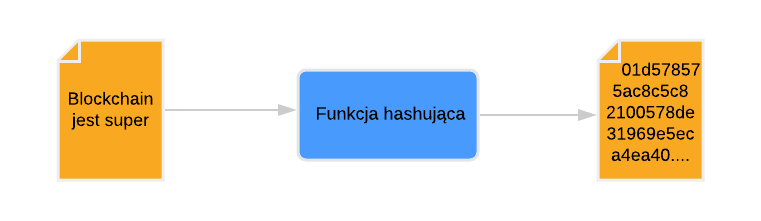
Hashowanie to proces nieodwracalny. Praktycznie, niemożliwym jest wygenerowanie oryginalnych danych wejściowych na podstawie hasha.Różne funkcje skrótu (zwane również funkcjami hashującymi) generują różnej długości hash (zwany również skrótem). Popularna funkcja SHA256 generuje hash długości 256 bitów, natomiast uznawana już za niebezpieczną funkcja MD5 generuje hash 128 bitowy.
MD5(chainkraft) = 428aa4bbd0dae9b27050f89492008ee2
SHA1(chainkraft) = 2ad43800879e33005089df2fbea6de0160e08f73
SHA256(chainkraft) = 95bc529ef76da85bb79d106aeef096d1b4c8fd93d67340f6d07bb8b01952a356
Keccak512(chainkraft) = 0bb2141d86ce67125303897970e409d08d25ff170104b87a3dcba5678610a93603f7227d325f48a6a982d709bf74e822606c1da88074e6a455104a9fa7a86b7aZastosowania
Funkcje skrótu znalazły szerokie zastosowanie dzięki swoim właściwościom. Poniżej prezentujemy kilka praktycznych implementacji.
Przechowywanie haseł
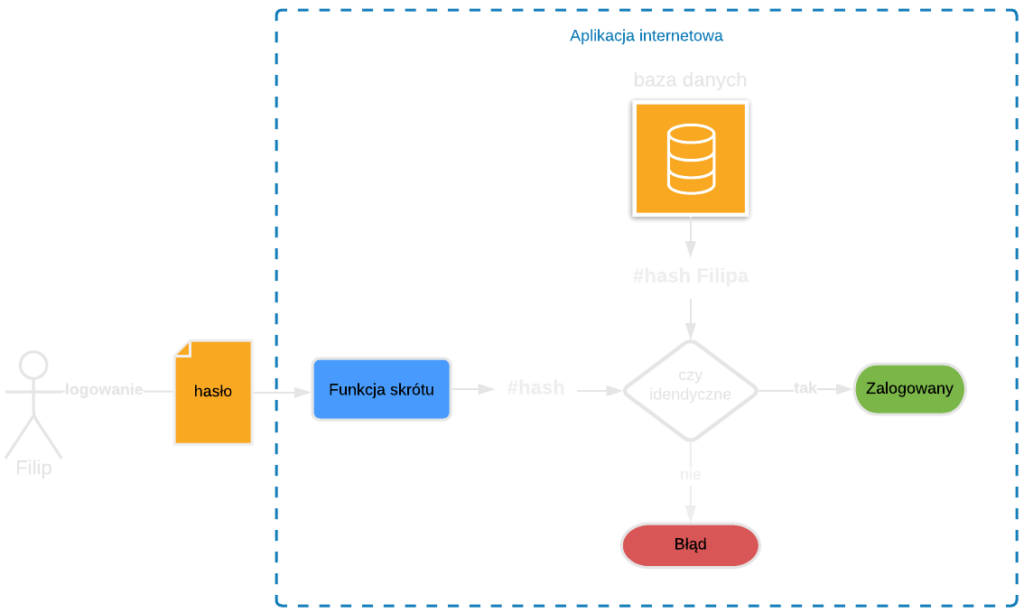
Dzięki jednokierunkowym właściwościom hashy, są one wykorzystywane do przechowywania skrótów haseł w systemach informatycznych. Praktycznie każda strona internetowa posiadająca opcję logowania przechowuje hasła użytkowników w bazie danych pod postacią hashy. Gdyby hasła użytkowników były przechowywane w postaci jawnej, mogłyby zostać wykradzione podczas ataku hakerskiego. Posiadając te same hasła w kilku portalach, atakujący mógłby uzyskać do nich dostęp za pomocą wykradzionego hasła.
Zdefiniowane przez użytkownika hasło do konta zostaje zahashowane i zapisane w bazie danych na etapie rejestracji. Podczas logowania użytkownika do systemu, wprowadzone hasło z formularza jest hashowane, a następnie porównywane z hashem przechowywanym w bazie danych (te same dane wejściowe wygenerują identyczny hash).
Integralność danych
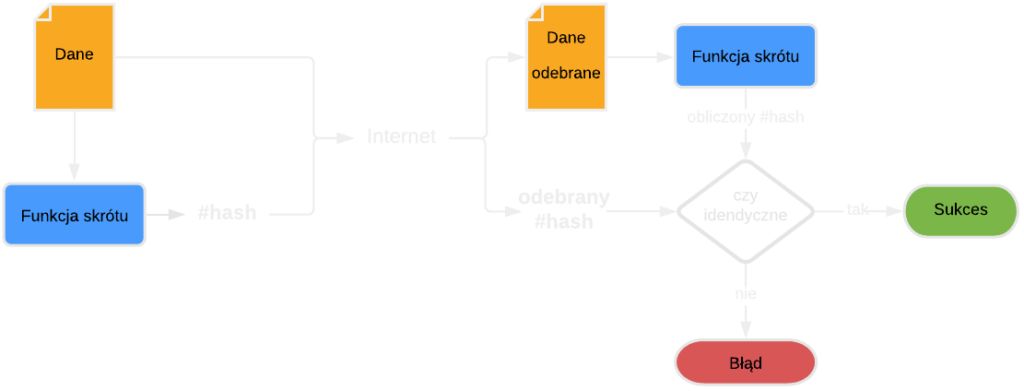
Kontrola integralności danych to najpopularniejsze zastosowanie funkcji hashujących. Funkcja generuje hash na podstawie danych (np. plik ze zdjęciem), który staje się tzw. sumą kontrolną (ang. checksum). Jest to swoisty odcisk palca danych. Nawet najmniejsza zmiana w strukturze danych spowoduje wygenerowanie innej sumy kontrolnej. Mechanizm pozwala na efektywną weryfikację danych przesyłanych przez sieć, gdzie odbiorca po ich odebraniu przeprowadza weryfikację.
Blockchain
Bez kryptograficznych skrótów danych, stworzenie wydajnej i bezpiecznej sieci Blockchain byłoby praktycznie niemożliwe. Bitcoin oraz wiele innych sieci blockchain wykorzystuje metodę dowodu pracy w procesie konsensusu, który zapewnia bezpieczeństwo sieci. Hashowanie to podstawowa operacja metody Proof of Work, której celem jest “wykopanie” nowego bloku zawierającego potwierdzone transakcje.
Hashe mają także inne zastosowania w Blockchain, służą m.in do generowania adresów, czy zapewniają możliwość szybkiej weryfikacji transakcji za pomocą drzew Merkele.
Właściwości
Przypomnimy teraz niektóre właściwości funkcji skrótu oraz poznamy właściwości ich specjalnej podgrupy – kryptograficznych funkcji skrótu.
Stałej długości hash
Niezależnie od wielkości danych wejściowych (może to być 1 kB danych lub plik 2GB) wynikowy hash powinien być stałej długości. Długość hasha zależy od użytej funkcji skrótu.
| Nazwa funkcji skrótu | Długość hasha [bit] |
|---|---|
| SHA-1 | 160 |
| SHA-256 | 256 |
| SHA-512 | 512 |
| RIPEMD-320 | 320 |
| Whirlpool | 512 |
Deterministyczność
Hash generowany na podstawie tych samych danych wejściowych powinien być identyczny.
hash1(test) = hash2(test) … = hashn(test)Jednak nawet najmniejsza zmiana w danych wejściowych powinna wygenerować zupełnie inny nieskorelowany hash (tzw. avalanche effect). Przykład:
hash(test) = 098f6bcd4621d373cade4e832627b4f6
hash(Test) = 0cbc6611f5540bd0809a388dc95a615bWydajność
Funkcje skrótu powinny być wydajne i szybkie podczas obliczenia hasha. Niezależnie od wielkości danych wejściowych, wynik powinien być zwrócony w bardzo krótkim czasie umożliwiając praktyczne zastosowanie algorytmu.
Pre-image resistance
Właściwość ta określa jednokierunkowość obliczeń hashy przez funkcje skrótu. Obliczenie hasha na podstawie danych wejściowych to jednokierunkowa operacja. Powinno być niemożliwym obliczenie danych wejściowych x na podstawie skrótu hash(x).

Second pre-image resistance
Mając dane wejściowe x, powinno być praktycznie niemożliwym znalezienie takich danych wejściowych y, dla których obliczony hash byłby taki sam: hash(x) != hash(y). Właściwość tą nazywa się również słabą odpornością na kolizje.
Odporność na kolizje
Właściwość ta definiuje wymaganie, że niezwykle trudno jest znaleźć dwie różne wartości wejściowe dla funkcji skrótu, które zwrócą ten sam hash: hash(x) != hash(y).
Ze względu na swoją naturę, funkcje skrótu zawsze będą generowały jakieś kolizje. Mamy nieskończoną ilość różnego rodzaju (i długości) danych wejściowych. Z kolei wygenerowany hash ma określoną maksymalną długość, dlatego ilość dostępnych kombinacji jest ograniczona. Chodzi o to, aby znalezienie takich kolizji było praktycznie niemożliwe.
Koncepcja algorytmu
Poniżej prezentujemy wysokopoziomowy opis działania typowej funkcji skrótu. Nie zagłębiamy się w detale, ponieważ w zależności od użytego algorytmu, mogą się one różnić znacznie.
Jak to jest, że funkcje skrótu generują hash o stałej długości na podstawie dowolnie długich danych wejściowych i hash ten jest identyczny z każdym wywołaniem funkcji? Wszystko za sprawą podstawowej koncepcji wykorzystywanej przez większość funkcji skrótu, która polega na podziale danych wejściowych na mniejsze bloki równiej długości w celu ich przetworzenia.
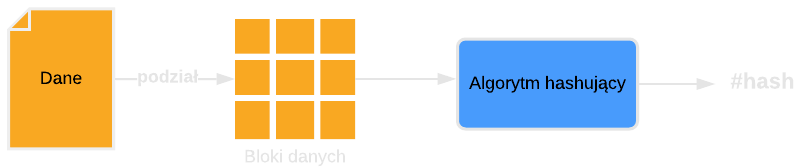
Wielkość bloku danych różni się w zależności od algorytmu. Przykładowo funkcja SHA-256 operuje na blokach danych wielkości 512 bitów. Zazwyczaj rozmiar danych wejściowych nie będzie wielokrotnością wielkości bloku. W takich przypadkach zastosowanie znajduje tzw. padding. Rozwiązanie polega na “uzupełnieniu” brakującej ilości danych, tak, aby ostatni blok po podziale również był stałej długości.
Po podziale danych na bloki stałej długości, można przystąpić do sekwencyjnego procesu obliczania hasha, który polega wywoływaniu algorytmu hashowania na każdym z bloków.
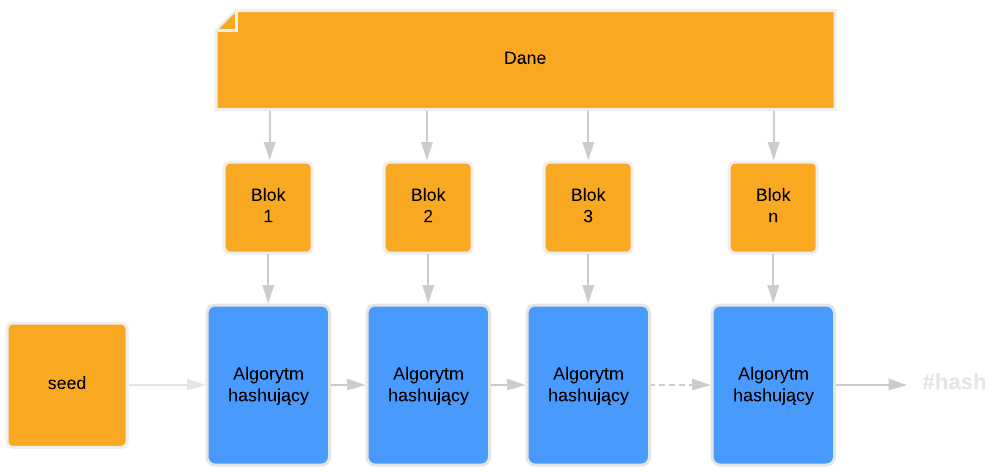
Funkcja jako parametry przyjmuje dane aktualnego bloku oraz wynik z obliczania skrótu poprzedniego bloku. Przykładowo podczas obliczania pierwszego bloku, funkcja przyjmuje dane z Bloku 1 oraz wartości inicjalizujące. Obliczenie drugiego bloku wymaga podania danych Bloku 2 oraz odpowiedzi z funkcji wywołanej na Bloku 1. Obliczenia są tak długo powtarzane, aż obliczone dane z ostatniego bloku zwrócą finalny hash.
W praktyce bloki liczone są nawet w kilkunastu rundach (np. SHA-256 wykorzystuje 80 rund), a wartość ostatniego hasha jest dodatkowo poddawana kompresji. Dzięki powiązaniu obliczeń algorytmu na odpowiedziach z poprzednich bloków, nawet zmiana jednego bitu danych, finalnie wygeneruje całkowicie inny hash (ang. avalanche effect).