What is fault tolerance?
Although distributed systems have been around for quite some time, they only rose to wider prominence with the growing popularity of the blockchain-based Bitcoin. Blockchain was designed as a network that does not need a centralized server, but requires its participants (nodes) to reconcile the state of the entire network with one another. The network stores all the decisions made by the nodes in a “ledger” that is accessible to every participant.
One of the fundamental issues with distributed systems lies in reaching an agreement when some nodes are unreliable. This may follow from many reasons, such as loss of network connection, a node being taken over by hackers, or simply a coding error.
System-level or individual component-level decentralization mechanisms are also used in such sectors as aviation, energy and space.

In the case of IT networks, a failure of a network participant may result in, for example, failure to deliver a message to the recipient or data becoming inaccessible. In industrial-grade systems, though, the stakes are much higher.
Picture a rocket worth hundreds of millions of dollars veering off course or shutting down an engine due to the one of its avionics modules failing. That could be extremely costly, so typically, for redundancy, several independent modules are installed, which communicate when a decision to change the flight parameters needs to be made. This makes the entire system more reliable and less prone to failure. When one of the modules fails completely or malfunctions, the failure will be detected when its decision is compared against the decisions made by the remaining reliable components. Systems capable of functioning properly in the event of errors and failures are called fault-tolerant systems.
What do medieval generals have in common with modern distributed systems?
The problem presented above was first formulated in 1982 at Microsoft Research by Marshall Pease, Leslie Lamport and Robert Shostak.
Imagine a few divisions of the Byzantine army surrounding an enemy city. Each unit is commanded by a general who will decide to either attack or retreat his divisions. All the divisions are deployed at a considerable distance from one another.
The generals must decide whether to attack or retreat. It doesn’t matter which option they choose as long as each unit behaves the same way. If they fail to launch a concerted attack, their forces will be defeated, and the city will hold out, but if they decide to retreat, the army will survive to fight another day.
The generals exchange messages containing their decisions through trusted messengers.
The main challenges posed by this situation are:
- messages delivered through messengers may fail to reach their destination or arrive too late
- some generals may be traitors who want the Byzantine army to be defeated
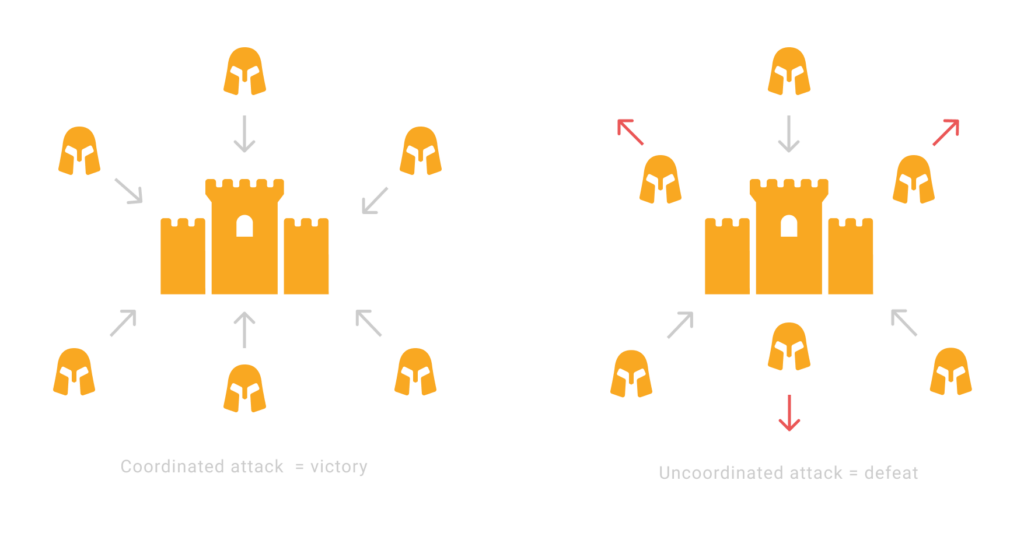
In this case, the attack consists in the traitors trying to convince loyal generals to make a decision detrimental to the system.
Example:
- General A decides to retreat and sends a messenger to carry his decision
- General B is a traitor and sends out messages claiming he would attack, which may sway the decisions of some generals opting to retreat
- General A receives a message from General B, decides to launch an attack and fails because General B is a traitor who had no intention of attacking the city
Let’s review an example from the original study by the algorithm’s makers as it adds into the mix a Commander who makes the initial decision, which is then shared between the Lieutenants.
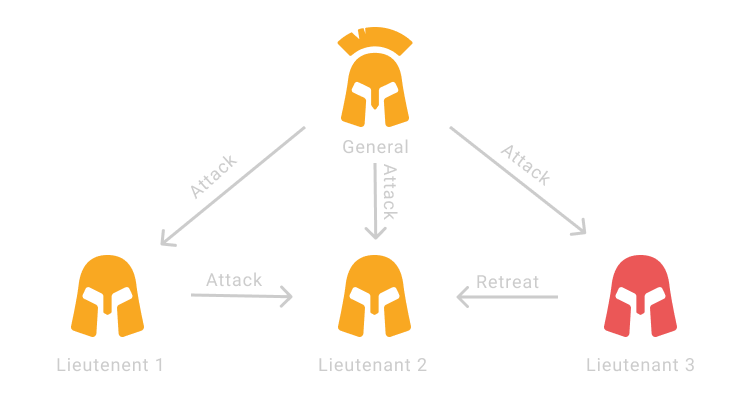
Now, let’s review the steps of the algorithm:
- The Commander sends his decision to attack to the lieutenants
- The Lieutenants pass the message from the Commander between themselves for confirmation
- Lieutenant 1 passes the true message to Lieutenant 2
- Lieutenant 3 (a traitor) sends a forged message to Lieutenant 2
- Lieutenant 2 conforms to the decision communicated to him by the majority of participants, which is to attack
- Thus, the network reaches a consensus for the Attack value because most of its members agreed with this decision
Translating the problem of Byzantine generals into computer networks, each general represents a node in a decentralized network. All nodes must reach a joint decision on the next network state (e.g. a new blockchain block) for the network to continue operating. If no consensus is reached, the network is paralyzed.
Byzantine fault tolerance
Byzantine Fault Tolerance is a system property that can resist a Byzantine attack related to the distributed nature of the network. If any of the nodes is damaged or infected, the entire system will still be able to make the right decision.
One crucial assumption here is the lack of assumptions regarding the expected behavior of individual network participants. The system does not suspect any node of malicious behavior but rather eliminates its effects at the stage of arriving at a consensus.From the point of view of a distributed Blockchain network, Byzantine Fault Tolerance is a key system property. The most popular consensus algorithms are Proof-of-Work and Proof-of-Stake, which offer protection against these types of attacks. Research on BFT algorithms picked up pace with the advent of blockchain technology and cryptocurrencies, spurring the development of increasingly effective methods of dealing with this dilemma.


